Additional Results for Paper 9784
Additional results for paper “Beta-CROWN: Efficient Bound Propagation with Per-neuron Split Constraints for Neural Network Robustness Verification” (Paper id: 9784)
On this page, we present the additional figures and tables as the reviewers requested. Detailed descriptions can be found in the main text of the rebuttal on OpenReview.
- We further improved the implementation of our verifier, leading to even stronger results (see updated updated Figure 1, updated Table 1, updated Table 2 and updated Table 3)
- We present extensive ablation studies, showing that handling split constraints is important and GPU acceleration is also crucial.
- We provide more comparisons to the Fast-and-Complete verifier.
New Experimental Results (Better Performance, and More Models Evaluated)
We provide an updated version for the main results tables and figures (Figure 1, Table 1,2,3 in our submission). The code submission used in our original submission was preliminary and not well optimized, and we have improved the implementation during the past few weeks. This allows us to demonstrate even stronger results. We additionally add a few MLP used in [33][35][26]. please see the updated tables and figures below.
Updated Figure1
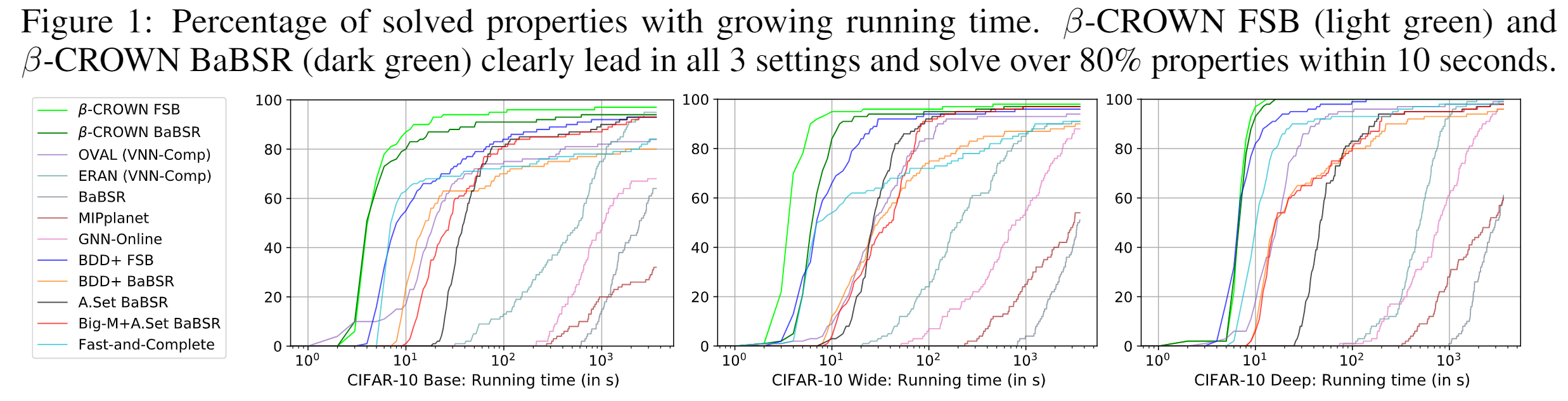
For all three CIFAR-10 Base, Wide and Deep models in updated Figure 1, we can now solve over 80% instances within just 10 seconds, and many existing methods take 10X longer time on the Base model.
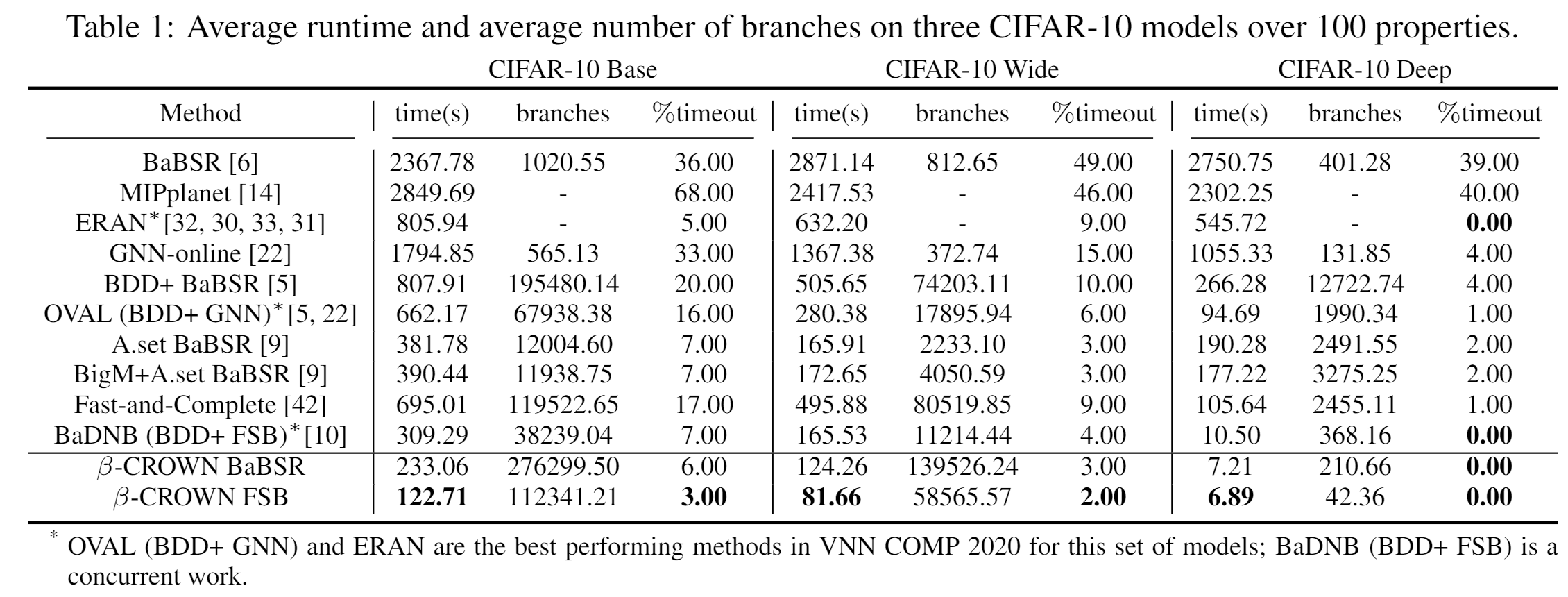
Updated Table1
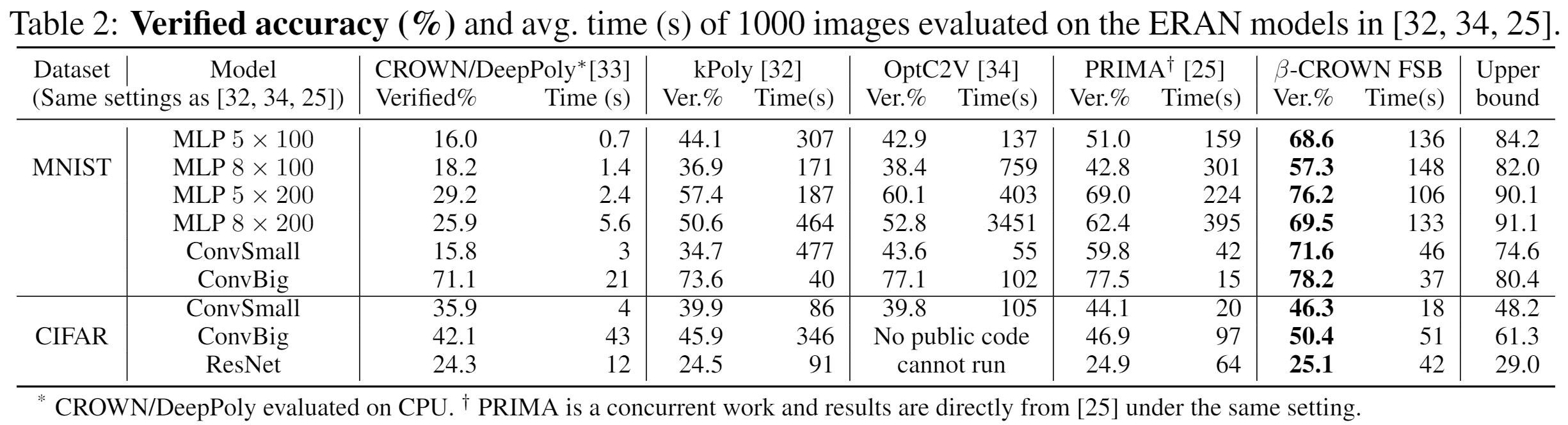
Updated Table2
In the updated Table 2, the verified accuracy is further improved, and verification time is reduced. We also added the new MLP models used in benchmarks of [26, 33, 35], for a more comprehensive evaluation. We strongly outperform existing methods.
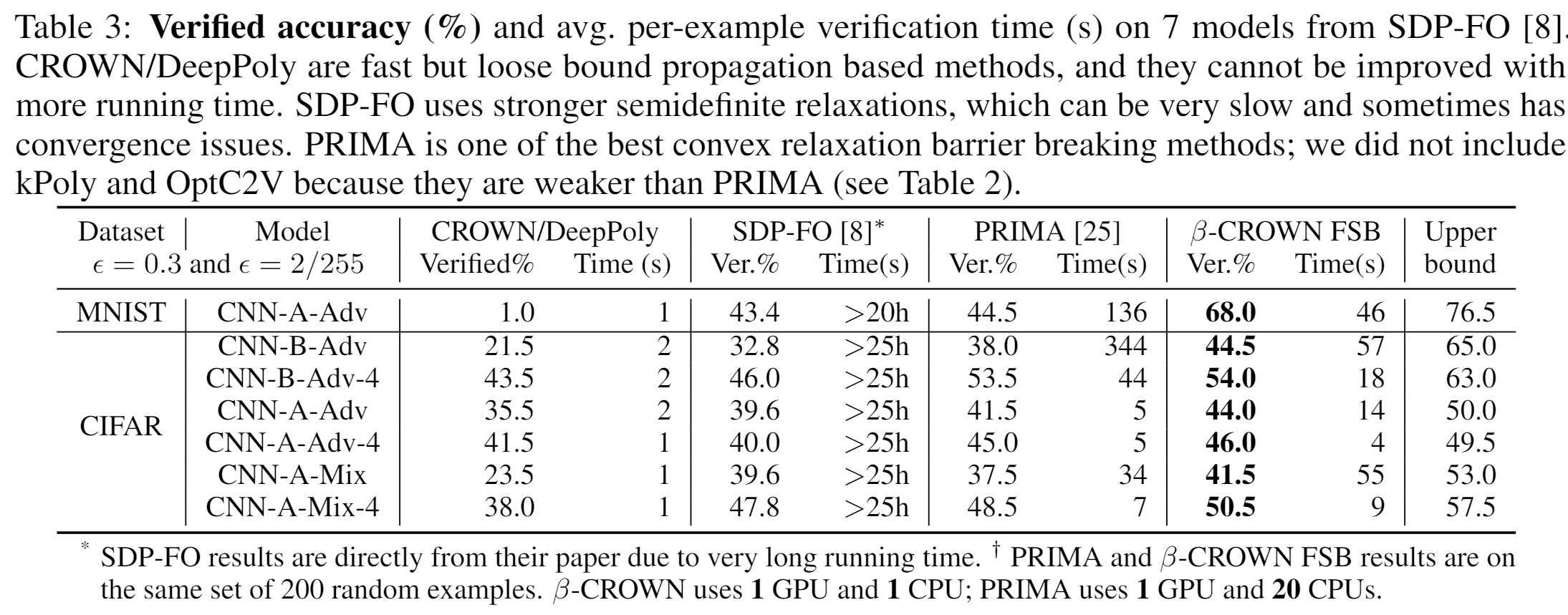
Updated Table3
Ablation Studies and New Experiments Requested by Reviewers
Table R1: Ablation study of running time on GPUs and CPUs
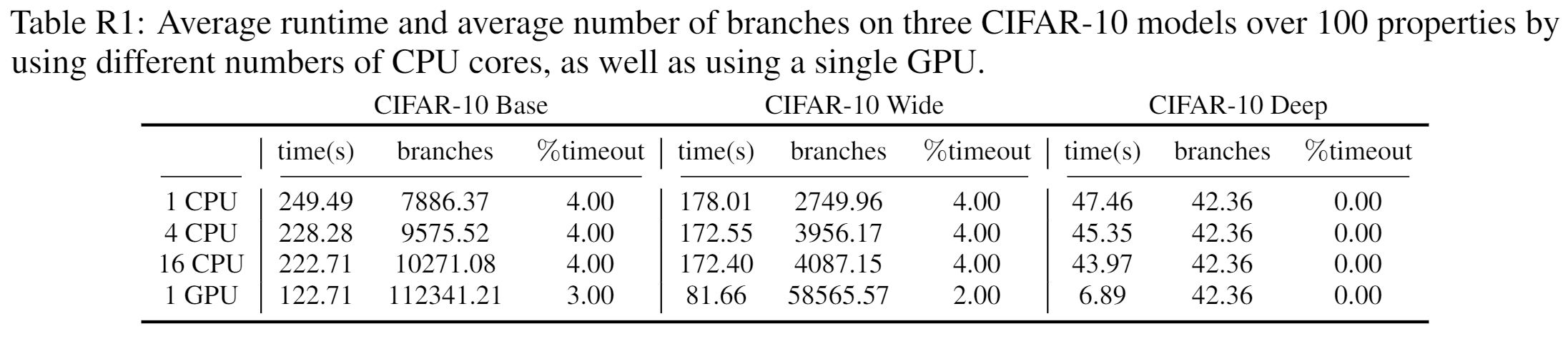
As shown in Table R1, the speedup on multi-core CPU is not ideal, possibly due to the limitation of PyTorch (we did set the number of threads correctly and observed that multiple CPU cores were utilized, but the speedup is very poor). GPU acceleration leads to We also note that these models are very small, and the benefits of GPU acceleration will be more obvious on larger models.
Table R2: Ablation study of alpha, beta, and joint optimization
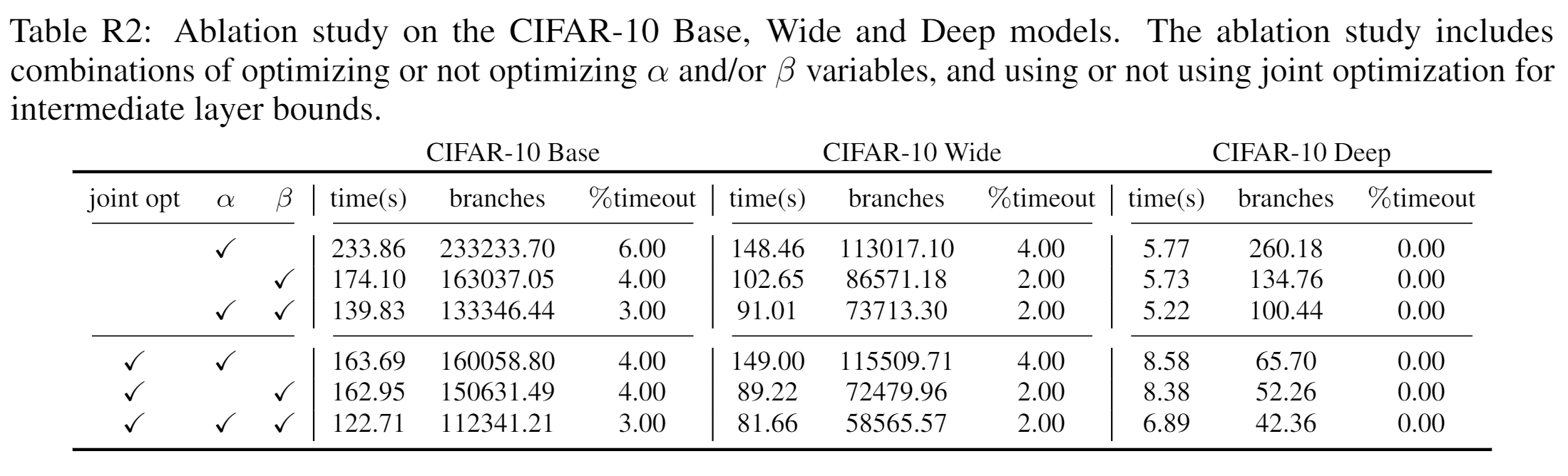
As shown in Table R2, optimizing both alpha and beta leads to optimal performance. Optimizing beta has greater impact than optimizing alpha. Joint optimization is helpful for CIFAR10-Base and CIFAR10-Wide models, reducing the overall runtime. For simple models like CIFAR10-Deep, disabling joint optimization can help slightly because this model is very easy to verify (within a few seconds) and using looser bounds reduces verification cost.
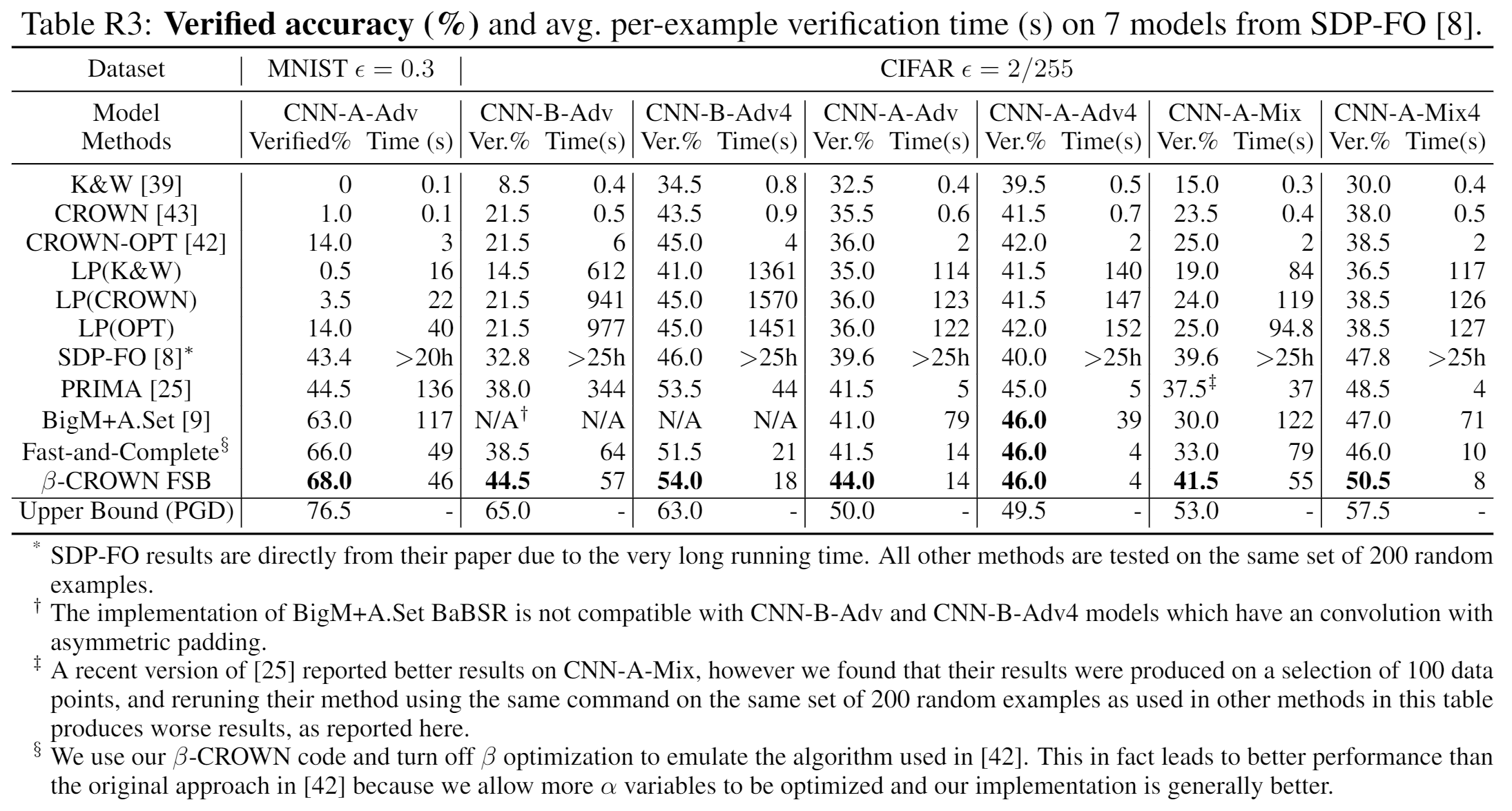
Table R3: Baseline results for Fast-and-Complete
In Table R3, we have now included the verified accuray for Fast-and-Complete [43]. It generally performs worse than ours in all settings.